
【導(dǎo)讀】前文說(shuō)過(guò),根據(jù)有限的訓(xùn)練集,去適應(yīng)無(wú)限的測(cè)試集,當(dāng)然訓(xùn)練集容量越大效果就越好。但是,訓(xùn)練集如果很大,那么每次都根據(jù)全部數(shù)據(jù)執(zhí)行梯度下降計(jì)算量就太大了。此時(shí),我們選擇每次只取全部訓(xùn)練集中的一小部分(究竟多少,一般根據(jù)內(nèi)存和計(jì)算量而定),執(zhí)行梯度下降,不斷的迭代,根據(jù)經(jīng)驗(yàn)一樣可以快速地把梯度降下來(lái)。這就是隨機(jī)梯度下降。
三、梯度的下降(下)
前文的梯度下降法只能對(duì)f函數(shù)的w權(quán)重進(jìn)行調(diào)整,而上文中我們說(shuō)過(guò)實(shí)際是多層函數(shù)套在一起,例如f1(f2(x;w2);w1),那么怎么求對(duì)每一層函數(shù)輸入的導(dǎo)數(shù)呢?這也是所謂的反向傳播怎樣繼續(xù)反向傳遞下去呢?這就要提到鏈?zhǔn)椒▌t。其實(shí)質(zhì)為,本來(lái)y對(duì)x的求導(dǎo),可以通過(guò)引入中間變量z來(lái)實(shí)現(xiàn),如下圖所示:
這樣,y對(duì)x的導(dǎo)數(shù)等價(jià)于y對(duì)z的導(dǎo)數(shù)乘以z對(duì)x的偏導(dǎo)。當(dāng)輸入為多維時(shí)則有下面的公式:
如此,我們可以得到每一層函數(shù)的導(dǎo)數(shù),這樣可以得到每層函數(shù)的w權(quán)重應(yīng)當(dāng)調(diào)整的步長(zhǎng),優(yōu)化權(quán)重參數(shù)。
由于函數(shù)的導(dǎo)數(shù)很多,例如resnet等網(wǎng)絡(luò)已經(jīng)達(dá)到100多層函數(shù),所以為區(qū)別傳統(tǒng)的機(jī)器學(xué)習(xí),我們稱其為深度學(xué)習(xí)。
深度學(xué)習(xí)只是受到神經(jīng)科學(xué)的啟發(fā),所以稱為神經(jīng)網(wǎng)絡(luò),但實(shí)質(zhì)上就是上面提到的多層函數(shù)前向運(yùn)算得到分類值,訓(xùn)練時(shí)根據(jù)實(shí)際標(biāo)簽分類取損失函數(shù)最小化后,根據(jù)隨機(jī)梯度下降法來(lái)優(yōu)化各層函數(shù)的權(quán)重參數(shù)。人臉識(shí)別也是這么一個(gè)流程。以上我們初步過(guò)完多層函數(shù)的參數(shù)調(diào)整,但函數(shù)本身應(yīng)當(dāng)如何設(shè)計(jì)呢?
四、基于CNN卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行人臉識(shí)別
我們先從全連接網(wǎng)絡(luò)談起。Google的TensorFlow游樂(lè)場(chǎng)里可以直觀的體驗(yàn)全連接神經(jīng)網(wǎng)絡(luò)的威力,這是游樂(lè)場(chǎng)的網(wǎng)址:http://playground.tensorflow.org/,瀏覽器里就可以做神經(jīng)網(wǎng)絡(luò)訓(xùn)練,且過(guò)程與結(jié)果可視化。如下圖所示:
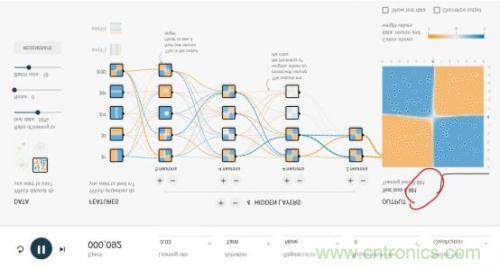
這個(gè)神經(jīng)網(wǎng)絡(luò)游樂(lè)場(chǎng)共有1000個(gè)訓(xùn)練點(diǎn)和1000個(gè)測(cè)試點(diǎn),用于對(duì)4種不同圖案劃分出藍(lán)色點(diǎn)與黃色點(diǎn)。DATA處可選擇4種不同圖案。
整個(gè)網(wǎng)絡(luò)的輸入層是FEATURES(待解決問(wèn)題的特征),例如x1和x2表示垂直或者水平切分來(lái)劃分藍(lán)色與黃色點(diǎn),這是最容易理解的2種劃分點(diǎn)的方法。其余5種其實(shí)不太容易想到,這也是傳統(tǒng)的專家系統(tǒng)才需要的,實(shí)際上,這個(gè)游樂(lè)場(chǎng)就是為了演示,1、好的神經(jīng)網(wǎng)絡(luò)只用最基本的x1,x2這樣的輸入層FEATURES就可以完美的實(shí)現(xiàn);2、即使有很多種輸入特征,我們其實(shí)并不清楚誰(shuí)的權(quán)重最高,但好的神經(jīng)網(wǎng)絡(luò)會(huì)解決掉這個(gè)問(wèn)題。
隱層(HIDDEN LAYERS)可以隨意設(shè)置層數(shù),每個(gè)隱層可以設(shè)置神經(jīng)元數(shù)。實(shí)際上神經(jīng)網(wǎng)絡(luò)并不是在計(jì)算力足夠的情況下,層數(shù)越多越好或者每層神經(jīng)元越多越好。好的神經(jīng)網(wǎng)絡(luò)架構(gòu)模型是很難找到的。本文后面我們會(huì)重點(diǎn)講幾個(gè)CNN經(jīng)典網(wǎng)絡(luò)模型。然而,在這個(gè)例子中,多一些隱層和神經(jīng)元可以更好地劃分。
epoch是訓(xùn)練的輪數(shù)。紅色框出的loss值是衡量訓(xùn)練結(jié)果的最重要指標(biāo),如果loss值一直是在下降,比如可以低到0.01這樣,就說(shuō)明這個(gè)網(wǎng)絡(luò)訓(xùn)練的結(jié)果好。loss也可能下降一會(huì)又突然上升,這就是不好的網(wǎng)絡(luò),大家可以嘗試下。learning rate初始都會(huì)設(shè)得高些,訓(xùn)練到后面都會(huì)調(diào)低些。Activation是激勵(lì)函數(shù),目前CNN都在使用Relu函數(shù)。
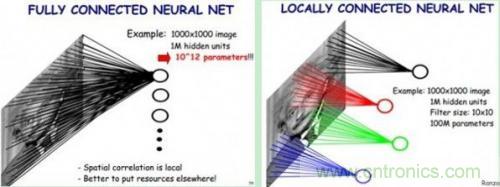
了解了神經(jīng)網(wǎng)絡(luò)后,現(xiàn)在我們回到人臉識(shí)別中來(lái)。每一層神經(jīng)元就是一個(gè)f函數(shù),上面的四層網(wǎng)絡(luò)就是f1(f2(f3(f4(x))))。然而,就像上文所說(shuō),照片的像素太多了,全連接網(wǎng)絡(luò)中任意兩層之間每?jī)蓚€(gè)神經(jīng)元都需要有一次計(jì)算。特別之前提到的,復(fù)雜的分類依賴于許多層函數(shù)共同運(yùn)算才能達(dá)到目的。當(dāng)前的許多網(wǎng)絡(luò)都是多達(dá)100層以上,如果每層都有3*100*100個(gè)神經(jīng)元,可想而知計(jì)算量有多大!于是CNN卷積神經(jīng)網(wǎng)絡(luò)應(yīng)運(yùn)而生,它可以在大幅降低運(yùn)算量的同時(shí)保留全連接網(wǎng)絡(luò)的威力。
CNN認(rèn)為可以只對(duì)整張圖片的一個(gè)矩形窗口做全連接運(yùn)算(可稱為卷積核),滑動(dòng)這個(gè)窗口以相同的權(quán)重參數(shù)w遍歷整張圖片后,可以得到下一層的輸入,如下圖所示:
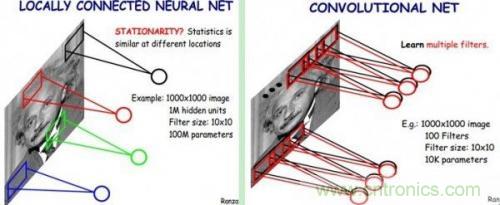
CNN中認(rèn)為同一層中的權(quán)重參數(shù)可以共享,因?yàn)橥粡垐D片的各個(gè)不同區(qū)域具有一定的相似性。這樣原本的全連接計(jì)算量過(guò)大問(wèn)題就解決了,如下圖所示:
結(jié)合著之前的函數(shù)前向運(yùn)算與矩陣,我們以一個(gè)動(dòng)態(tài)圖片直觀的看一下前向運(yùn)算過(guò)程:
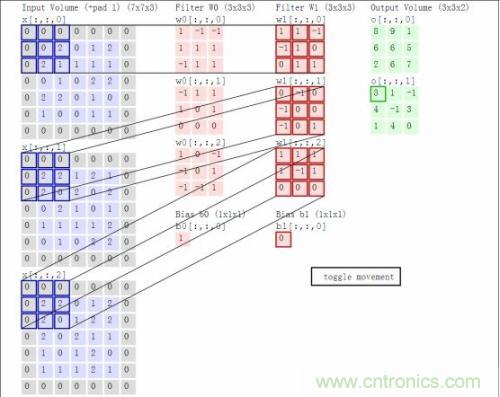
這里卷積核大小與移動(dòng)的步長(zhǎng)stride、輸出深度決定了下一層網(wǎng)絡(luò)的大小。同時(shí),核大小與stride步長(zhǎng)在導(dǎo)致上一層矩陣不夠大時(shí),需要用padding來(lái)補(bǔ)0(如上圖灰色的0)。以上就叫做卷積運(yùn)算,這樣的一層神經(jīng)元稱為卷積層。上圖中W0和W1表示深度為2。
CNN卷積網(wǎng)絡(luò)通常在每一層卷積層后加一個(gè)激勵(lì)層,激勵(lì)層就是一個(gè)函數(shù),它把卷積層輸出的數(shù)值以非線性的方式轉(zhuǎn)換為另一個(gè)值,在保持大小關(guān)系的同時(shí)約束住值范圍,使得整個(gè)網(wǎng)絡(luò)能夠訓(xùn)練下去。在人臉識(shí)別中,通常都使用Relu函數(shù)作為激勵(lì)層,Relu函數(shù)就是max(0,x),如下所示:
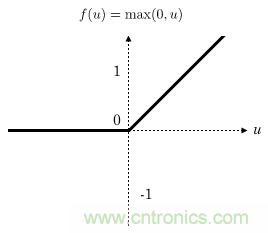
可見 Relu的計(jì)算量其實(shí)非常小!
CNN中還有一個(gè)池化層,當(dāng)某一層輸出的數(shù)據(jù)量過(guò)大時(shí),通過(guò)池化層可以對(duì)數(shù)據(jù)降維,在保持住特征的情況下減少數(shù)據(jù)量,例如下面的4*4矩陣通過(guò)取最大值降維到2*2矩陣:

上圖中通過(guò)對(duì)每個(gè)顏色塊篩選出最大數(shù)字進(jìn)行池化,以減小計(jì)算數(shù)據(jù)量。
通常網(wǎng)絡(luò)的最后一層為全連接層,這樣一般的CNN網(wǎng)絡(luò)結(jié)構(gòu)如下所示:
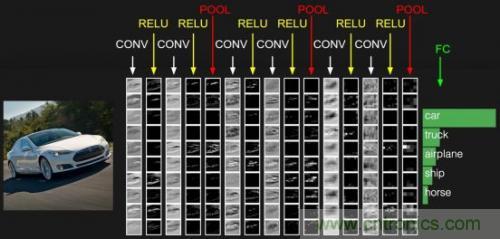
CONV就是卷積層,每個(gè)CONV后會(huì)攜帶RELU層。這只是一個(gè)示意圖,實(shí)際的網(wǎng)絡(luò)要復(fù)雜許多。目前開源的Google FaceNet是采用resnet v1網(wǎng)絡(luò)進(jìn)行人臉識(shí)別的,關(guān)于resnet網(wǎng)絡(luò)請(qǐng)參考論文https://arxiv.org/abs/1602.07261,其完整的網(wǎng)絡(luò)較為復(fù)雜,這里不再列出,也可以查看基于TensorFlow實(shí)現(xiàn)的Python代碼https://github.com/davidsandberg/facenet/blob/master/src/models/inception_resnet_v1.py,注意slim.conv2d含有Relu激勵(lì)層。
以上只是通用的CNN網(wǎng)絡(luò),由于人臉識(shí)別應(yīng)用中不是直接分類,而是有一個(gè)注冊(cè)階段,需要把照片的特征值取出來(lái)。如果直接拿softmax分類前的數(shù)據(jù)作為特征值效果很不好,例如下圖是直接將全連接層的輸出轉(zhuǎn)化為二維向量,在二維平面上通過(guò)顏色表示分類的可視化表示:
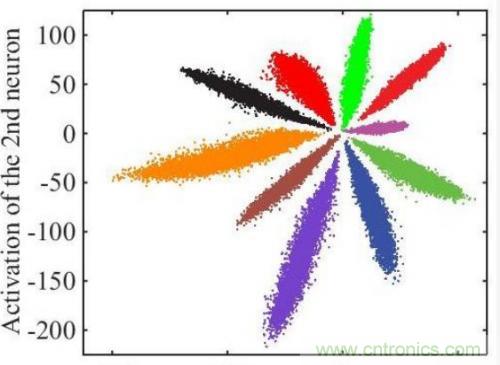
可見效果并不好,中間的樣本距離太近了。通過(guò)centor loss方法處理后,可以把特征值間的距離擴(kuò)大,如下圖所示:

這樣取出的特征值效果就會(huì)好很多。
實(shí)際訓(xùn)練resnet v1網(wǎng)絡(luò)時(shí),首先需要關(guān)注訓(xùn)練集照片的質(zhì)量,且要把不同尺寸的人臉照片resize到resnet1網(wǎng)絡(luò)首層接收的尺寸大小。另外除了上面提到的學(xué)習(xí)率和隨機(jī)梯度下降中每一批batchsize圖片的數(shù)量外,還需要正確的設(shè)置epochsize,因?yàn)槊恳惠唀poch應(yīng)當(dāng)完整的遍歷完訓(xùn)練集,而batchsize受限于硬件條件一般不變,但訓(xùn)練集可能一直在變大,這樣應(yīng)保持epochsize*batchsize接近全部訓(xùn)練集。訓(xùn)練過(guò)程中需要密切關(guān)注loss值是否在收斂,可適當(dāng)調(diào)節(jié)學(xué)習(xí)率。
最后說(shuō)一句,目前人臉識(shí)別效果的評(píng)價(jià)唯一通行的標(biāo)準(zhǔn)是LFW(即Labeled Faces in the Wild),它包含大約6000個(gè)不同的人的12000張照片,許多算法都依據(jù)它來(lái)評(píng)價(jià)準(zhǔn)確率。但它有兩個(gè)問(wèn)題,一是數(shù)據(jù)集不夠大,二是數(shù)據(jù)集場(chǎng)景往往與真實(shí)應(yīng)用場(chǎng)景并不匹配。所以如果某個(gè)算法稱其在LFW上的準(zhǔn)確率達(dá)到多么的高,并不能反應(yīng)其真實(shí)可用性。

