
隨著互聯網用戶的快速增長,數據體量的急劇膨脹,數據中心對計算的需求也在迅猛上漲。同時,人工智能、高性能數據分析和金融分析等計算密集型領域的興起,對計算能力的需求已遠遠超出了傳統CPU處理器的能力所及。
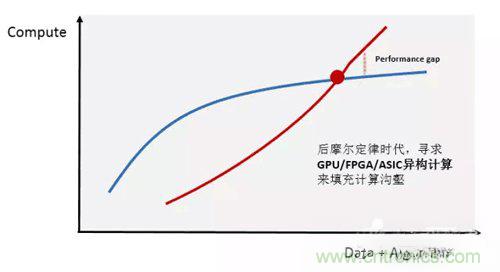
異構計算被認為是現階段解決此計算溝壑的關鍵技術,目前 “CPU+GPU”以及“CPU+FPGA” 是最受業界關注的異構計算平臺。它們具有比傳統CPU并行計算更高效率和更低延遲的計算性能優勢。面對如此巨大的市場,科技行業大量企業投入了大量的資金和人力,異構編程的開發標準也在逐漸成熟,而主流的云服務商更是在積極布局。

WHY?通用CNN FPGA加速
業界可以看到諸如微軟等巨頭公司已經部署大批量的FPGA來做AI inference加速,FPGA相較于其他器件的優勢是什么呢?
Flexibility:可編程性天然適配正在快速演進的ML算法
DNN、CNN、LSTM、MLP、reinforcement learning以及決策樹等等
任意精度動態支持
模型壓縮、稀疏網絡、更快更好的網絡
Performance:構建實時性AI服務能力
相較于GPU/CPU數量級提升的低延時預測能力
相較于GPU/CPU數量級提升的單瓦特性能能力
Scale
板卡間高速互聯IO
Intel CPU-FPGA構架
與此同時,FPGA的短板也非常的明顯,FPGA使用HDL硬件描述語言來進行開發,開發周期長,入門門檻高。以單獨的經典模型如Alexnet以及Googlenet為例,針對一個模型進行定制的加速開發,往往需要數月的時間。業務方以及FPGA加速團隊需要兼顧算法迭代以及適配FPGA硬件加速,十分痛苦。
一方面需要FPGA提供相較于CPU/GPU有足夠競爭力的低延時高性能服務,一方面需要FPGA的開發周期跟上深度學習算法的迭代周期,基于這兩點我們設計開發了一款通用的CNN加速器。兼顧主流模型算子的通用設計,以編譯器產生指令的方式來驅動模型加速,可以短時間內支持模型切換;同時,對于新興的深度學習算法,在此通用基礎版本上進行相關算子的快速開發迭代,模型加速開發時間從之前的數月降低到現在的一到兩周之內。
HOW?通用CNN FPGA架構
基于FPGA的通用CNN加速器整體框架如下,通過Caffe/Tensorflow/Mxnet等框架訓練出來的CNN模型,通過編譯器的一系列優化生成模型對應的指令;同時,圖片數據和模型權重數據按照優化規則進行預處理以及壓縮后通過PCIe下發到FPGA加速器中。FPGA加速器完全按照指令緩沖區中的指令集驅動工作,加速器執行一遍完整指令緩沖區中的指令則完成一張圖片深度模型的計算加速工作。每個功能模塊各自相對獨立,只對每一次單獨的模塊計算請求負責。加速器與深度學習模型相抽離,各個layer的數據依賴以及前后執行關系均在指令集中進行控制。
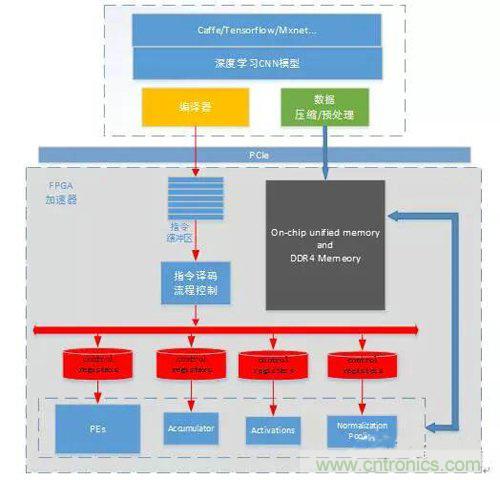
簡單而言,編譯器的主要工作就是對模型結構進行分析優化,然后生成FPGA高效執行的指令集。編譯器優化的指導思想是:更高的MAC dsp計算效率以及更少的內存訪問需求。
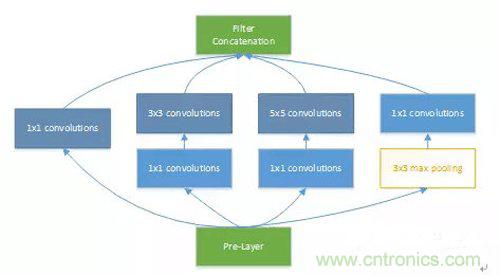
接下來我們以Googlenet V1模型為例,對加速器的設計優化思路做簡單的分析。IncepTIon v1的網絡,將1x1、3x3、5x5的conv和3x3的pooling stack在一起,一方面增加了網絡的width,另一方面增加了網絡對尺度的適應性。下圖為模型中IncepTIon的基本結構。
數據依賴關系分析
此部分主要分析挖掘模型中可流水化以及可并行化的計算。流水化的設計可以提高加速器中的計算單元利用率,并行化的計算可以在同一時刻利用盡量多的計算單元。
關于流水,分析部分包括數據從DDR加載到FPGA片上SRAM的操作與PE進行計算的流水,通過此項優化將內存訪問的時間overlap;DSP計算整列的計算控制過程,保證DSP利用率的提升。
關于并行,需要重點分析PE計算陣列與激活、pooling以及歸一化等“后處理”模塊之間的并行關系,如何確定好數據依賴關系以及防止沖突是此處設計關鍵。在IncepTIon中,可以從其網絡結構中看到,branch a/b/c的1x1的卷積計算與branch d中的pooling是可以并行計算的,兩者之間并不存在數據依賴關系。通過此處優化,3x3 max pooling layer的計算就可以被完全overlap。
模型優化
在設計中主要考慮兩個方面:尋找模型結構優化以及支持動態精度調整的定點化。
FPGA是支持大量計算并行的器件,從模型結構上尋找更高維度的并行性,對于計算效率以及減少內存訪問都十分有意義。在IncepTIon V1中,我們可以看到branch a branch b branch c的第一層1x1卷積層,其輸入數據完全一致,且卷積layer的stride以及pad均一致。那我們是否可以在output feature map維度上對齊進行疊加?疊加后對input data的訪存需求就降低到了原來的1/3。
另一方面,為了充分發揮FPGA硬件加速的特性,模型的Inference過程需要對模型進行定點化操作。在fpga中,int8的性能可以做到int16的2倍,但是為了使公司內以及騰訊云上的客戶可以無感知的部署其訓練的浮點模型,而不需要retrain int8模型來控制精度損失,我們采用了支持動態精度調整的定點化int16方案。通過此種方法,用戶訓練好的模型可以直接通過編譯器進行部署,而幾乎無任何精度損失。
內存架構設計
帶寬問題始終是計算機體系結構中制約性能的瓶頸之一,同時內存訪問直接影響加速器件功耗效率。
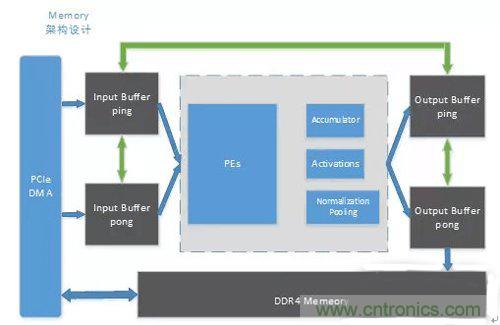
為了最大化的減少模型計算過程中的DDR訪存,我們設計了如下的內存架構:
Input buff以及output buffer ping-pong設計,最大化流水以及并行能力
支持Input buff和output buffer自身之間的inner-copy操作
Input buff和output buffer之間的cross-copy操作
通過這種架構,對于大多數目前主流模型,加速器可以做到將中間數據全部hold在FPGA片上,除了模型權重的加載外,中間無需消耗任何額外的內存操作。對于無法將中間層feature map完全存儲在片上的模型,我們在設計上,在Channel維度上引入了slice分片的概念,在feature map維度上引入了part分片的概念。通過編譯器將一次卷積或是poolingNorm操作進行合理的拆分,將DDR訪存操作與FPGA加速計算進行流水化操作,在優先保證DSP計算效率的前提下盡量減少了DDR的訪存需求。
計算單元設計
基于FPGA的通用CNN加速器的核心是其計算單元,本加速器當前版本基于Xilinx Ku115芯片設計,PE計算單元由4096個工作在500MHz的MAC dsp核心構成,理論峰值計算能力4Tflops。其基本組織框架如下圖所示。
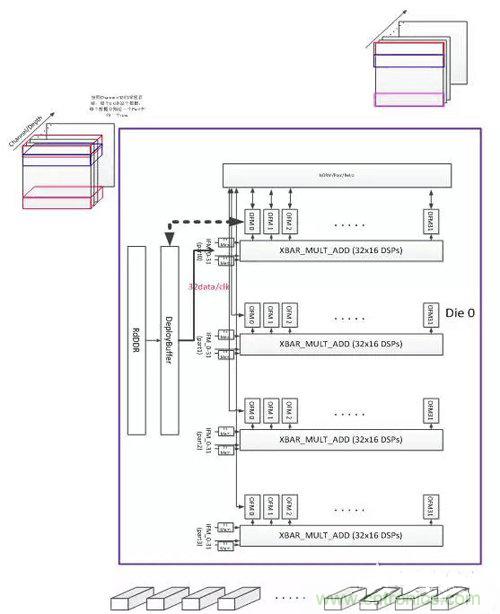
KU115芯片由兩個DIE對堆疊而成,加速器平行放置了兩組處理單元PE。每個PE由4組32x16=512的MAC計算DSP核心組成的XBAR構成,設計的關鍵在于提升設計中的數據復用降低帶寬,實現模型權重復用和各layer feature map的復用,提升計算效率。
應用場景及性能對比
當前深度學習主流使用GPU做深度學習中的Training過程,而線上Inference部署時需綜合考慮實時性、低成本以及低功耗特性選擇加速平臺。按深度學習落地場景分類,廣告推薦、語音識別、圖片/視頻內容實時監測等屬于實時性AI服務以及智慧交通、智能音箱以及無人駕駛等終端實時低功耗的場景,FPGA相較于GPU能夠為業務提供強有力的實時高性能的支撐。
對于使用者而言,平臺性能、開發周期以及易用性究竟如何呢?
加速性能
以實際googlenet v1模型為例,CPU測試環境:2個6核CPU(E5-2620v3),64G內存。
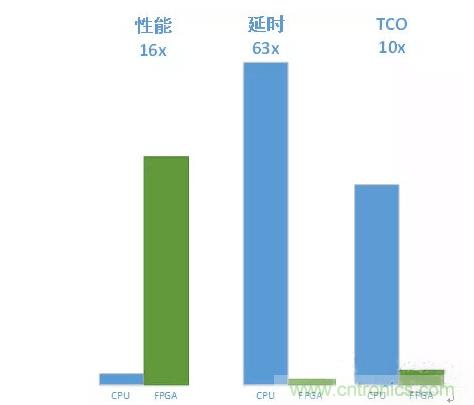
將整機CPU打滿,單張基于KU115的加速器相較于CPU性能提升16倍,單張圖片檢測延時從250ms降低到4ms,TCO成本降低90%。
同時,FPGA預測性能略強于Nvidia的GPU P4,但延時上有一個數量級的優化。
開發周期
通用的CNN FPGA加速架構,能夠支持業務快速迭代持續演進中的深度學習模型,包括Googlenet/VGG/Resnet/ShuffleNet/MobileNet等經典模型以及新的模型變種。
對于經典模型以及基于標準layer自研的算法變種,現有加速架構已經可以支持,可以在一天內通過編譯器實現模型對應指令集,實現部署上線。
對于自研的特殊模型,例如不對稱卷積算子和不對稱pooling操作等,需要根據實際模型結構在本平臺上進行相關算子迭代開發,開發周期可縮短在一到兩周之內進行支持。
易用性
FPGA CNN加速器對底層加速過程進行封裝,向上對加速平臺的業務方提供易用SDK。業務方調用簡單的API函數即可完成加速操作,對業務自身邏輯幾乎無任何改動。
如果線上模型需要改動,只需調用模型初始化函數,將對應的模型指令集初始化FPGA即可,加速業務可以在幾秒內進行切換。
結語
基于FPGA的通用CNN加速設計,可以大大縮短FPGA開發周期,支持業務深度學習算法快速迭代;提供與GPU相媲美的計算性能,但擁有相較于GPU數量級的延時優勢。通用的RNN/DNN平臺正在緊張研發過程中,FPGA加速器為業務構建最強勁的實時AI服務能力。
在云端,2017年初,我們在騰訊云首發了國內第一臺FPGA公有云服務器,我們將會逐步把基礎AI加速能力推出到公有云上。
AI異構加速的戰場很大很精彩,為公司內及云上業務提供最優的解決方案是架平FPGA團隊持續努力的方向。
推薦閱讀:
基于SoC FPGA進行工業設計及電機控制
結合實例解讀模擬開關關鍵技術
不可不知的射頻測試探針基本知識
一文讀懂DC/AC SCAN測試技術


